





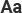

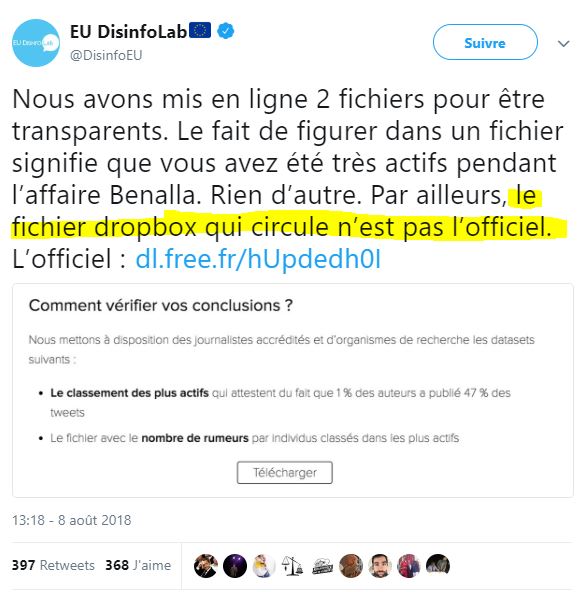
Après avoir montré des lacunes méthodologiques dans leur étude, puis leur inconscience dans le traitement de données personnelles sensibles et la création d’un fichage politique, puis leur irresponsabilité dans la diffusion publiques de ces données, voilà maintenant que le DisinfoLab donne dans… la Désinformation et les Fake News.
I. Rappel des faits sur le fichage de EU DisinfoLab
Rappelons que l’association belge EU DisinfoLab (créée le 27 décembre 2017) a acheté un accès à Visibrain, applicatif qui lui donne accès à TOUTE la base Twitter. Avec, ils ont récupéré les 247 701 comptes qui ont fait au moins un tweet ou un retweet sur l’affaire Benalla, et ont aspiré un certain nombre d’informations sur les dilatateurs figurant dans la base.
Ils ont alors créé un autre fichier comprenant les 55 000 comptes qui ont produit plus de 7 (re)tweets, et comprenant de nombreuses informations personnelles sensibles auxquelles ce fichier permet d’accéder instantanément. La plupart figurent dans la Biographie du profil (rédigée par l’utilisateur) ; il est à noter que ces informations permettent de faire une recherche ciblée sur un indicateur de religion, d’orientation sexuelle, d’opinion politique, etc., et de faire des regroupements très facilement. Bien que les données soient indiquées publiquement par le titulaire du compte, il faut savoir qu’il n’est pas possible de les retrouver avec une utilisation « classique » du moteur de recherche Twitter (essayez donc de trouver 200 personnes ayant indiqué être bouddhistes dans leur biographie… C’est impossible pour 99 % des utilisateurs). Il faut payer Twitter pour cela.
EU DisinfoLab a ensuite extrait plus de 3 000 profils qui ont produit plus de 200 (re)tweets, avec les informations précédentes auxquelles s’ajoute une classification réalisée par un algorithme qu’ils ont créé qui donne une couleur politique à ces comptes d’opposants (« Souverainiste », « Extrême Droite » ou « France Insoumise »).
Le 5 août, Nicolas Vanderbiest, fondateur d’EU DisinfoLab, a alors diffusé sur Twitter les 2 fichiers (« Data brutes.csv » pour les 55 000 et « ActeursClassés.xlsx » pour le fichage politique), qui ont alors circulé sur Twitter – ne tenant pas compte des demandes pressantes de suppression du fichier (exemples ici, ici, ici ou ici). Il a fini par supprimer les fichiers 4 jours après, suite à une masse de plaintes à la CNIL, qui s’est saisie du dossier. EU DisinfoLab a alors diffusé, via dl.free.fr, un fichier zip comprenant 2 fichiers « allégés », lien donné sur Twitter (26 fois…) et dans leur étude Benalla, sans données personnelles ni politiques (« Data brutes 1 – 47.xlsx » et « Rumeurs & items.xlsx »), mais comprenant le nombre de rumeurs supposément diffusées par les plus de 3 000 acomptes très actifs, avant de supprimer également ces fichiers sur dl.free.fr le 9 aout à 18h38 (source : étude Benalla DisinfoLab).


II. Nos tweets du 10 août 2018
Afin que chacun comprenne la problématique de ces fichiers 1/ comprenant des masses de données sensibles, certes fournies publiquement (mais de façon discrète, à sa communauté de followers, généralement limitée) et 2/ du fichage politique réalisé par algorithme EU Disinfolab, nous avons réalisé des tweets avec une extraction (que nous avons anonymisée) de certains profils présentant des informations très sensibles :
À ceux qui minimisent le #FichagePolitique de DisinfoLab, voici un extrait anonymisé des 2 fichiers qu’ils ont créés et diffusés.
Quelles que soient nos convictions politiques, nous devrions tous nous réunir pour lutter contre ça. C’est ce qui avait permis la création de la @CNIL pic.twitter.com/FWpvHljCAv— Olivier Berruyer (@OBerruyer) 10 août 2018
Afin que tout soit bien clair, nous avons réalisé un rappel des faits en thread :
Rappels importants sur l’affaire DisinfoLab. Un dossier détaillé est disponible ici : https://t.co/kqKm6RNiis pic.twitter.com/3ODCJGMLJ6
— Olivier Berruyer (@OBerruyer) 10 août 2018
Puis nous avons alerté les partis politiques et associations concernées :
Que pensez-vous de modifier la loi pour une meilleure protection de nos données personnelles pour éviter tout fichage ? @FranceInsoumise @partisocialiste @enmarchefr @gouvernementFR @lesRepublicains @DLF_Officiel @RNational_off @CNIL @_LICRA_ @LDH_Fr @amnestyfrance @laquadrature pic.twitter.com/Cu8DzHiWvq
— Olivier Berruyer (@OBerruyer) 10 août 2018
N’hésitez d’ailleurs pas à les retweeter.
III. Le Communiqué EU DisinfoLab du 11 août 2018
Nous avons alors eu la surprise de lire ce communiqué de EU Disinfo Lab :
11/08/2018 : Communiqué de presse – Fausses captures d’écran
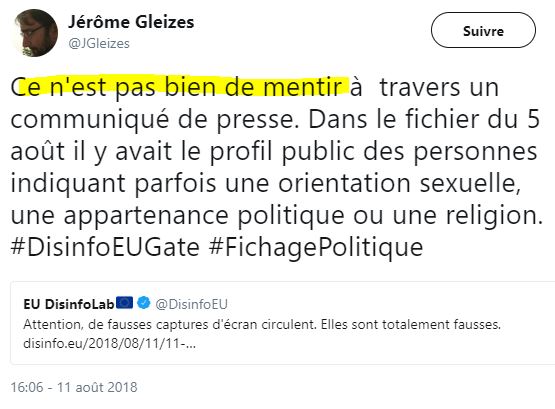
Nous remarquons qu’une capture d’écran circule actuellement sur Twitter, Facebook et des sites d’information mettant en cause un des fichiers que nous avons transmis. Sur cette capture d’écran apparaissent des mots surlignés qui feraient penser qu’il y aurait des personnes « gay », « lesbienne », « juifs ». Aucune de ces biographies n’est issue du fichier. Tout un chacun pourra le vérifier simplement en faisant une recherche dans les fichiers. Il pourra constater que :
- Le nombre de tweets affichés sur la capture d’écran est impossible. Seules les personnes avec + de 200 tweets étaient rassemblées.
- Les localisations ne faisaient pas partie des fichiers que nous avons transmis. Par ailleurs, nous nous étonnons d’une localisation « marié gay en prc »
Par ailleurs, nous rappelons que le premier fichier de 55 000 pseudonymes ne comprenait que les pseudonymes des personnes ayant tweeté sur le sujet et le nombre de tweets. Rien d’autre.Nous regrettons vivement le climat de désinformation qui règne autour de cette affaire et rappelons que, conformément au RGPD, les personnes concernées peuvent faire valoir leur droits d’effacement légitimes en nous contactant par e-mail à droitdacces@disinfo.euSource : Disinfo.eu (archive)
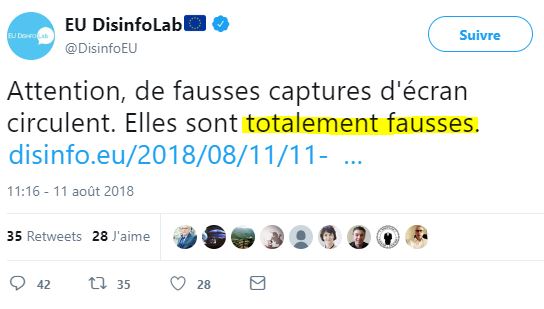
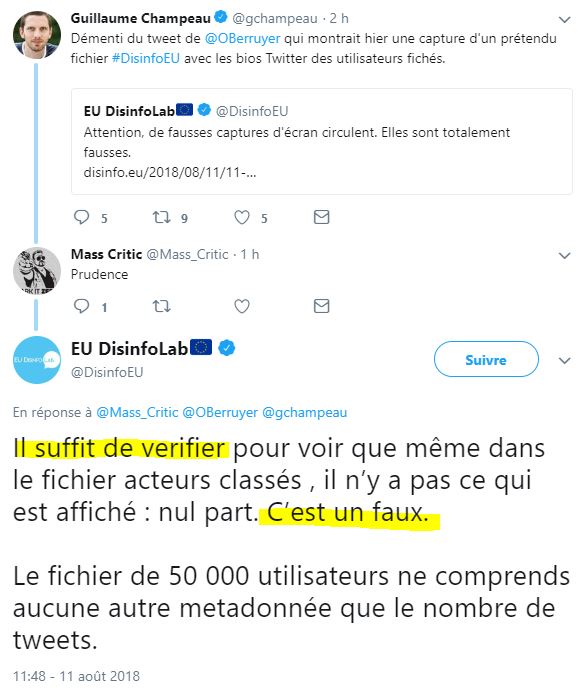
Ce mensonge fait évidemment réagir :
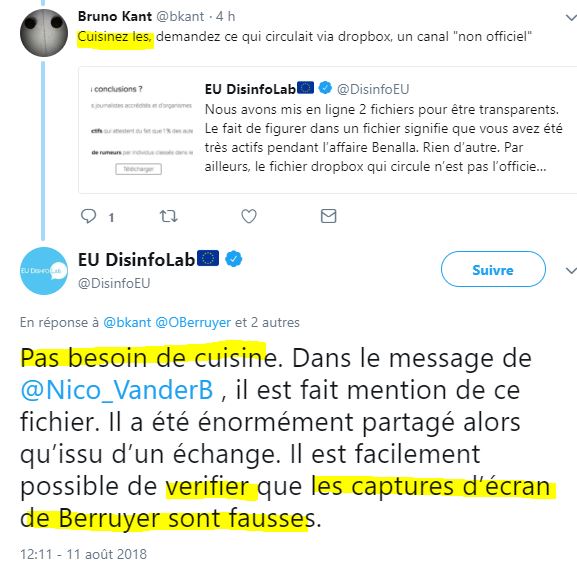
Si, si, la cuisine est nécessaire…
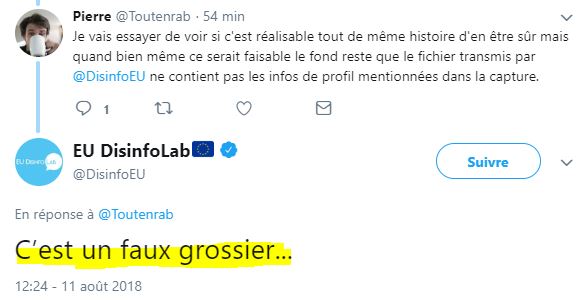
Puis vient alors l’instant complotisme délirant :
Ils indiquent donc que nous aurions NOUS-MÊMES créé le fichier, en recopiant à la main via l’API Twitter, 100 par 100, 55 000 profils Twitter (ce qu’elle ne permet pas), et d’ailleurs pour classer correctement et arriver au même fichier qu’eux, ce sont les 4 300 000 (re) tweets qu’il aurait fallu récupérer (et dommage, on ne peut récupérer plus de quelques retweets sans l’API)
Nous plaignons Pierre, ce twittos qui, encouragé par eux, aura passé son samedi après-midi à essayer de voir si ce délire est crédible… Quel manque de respect envers les citoyens vigilants !
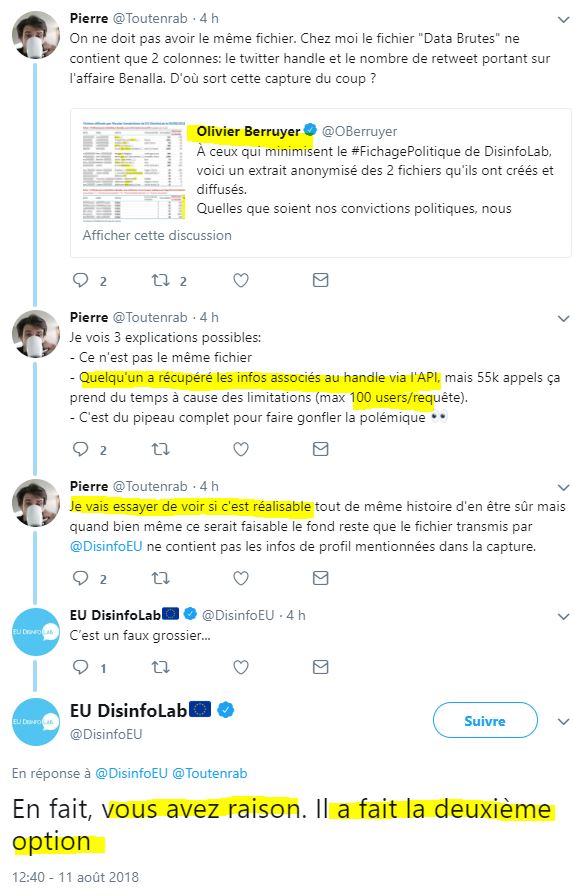
Et ils insistent :
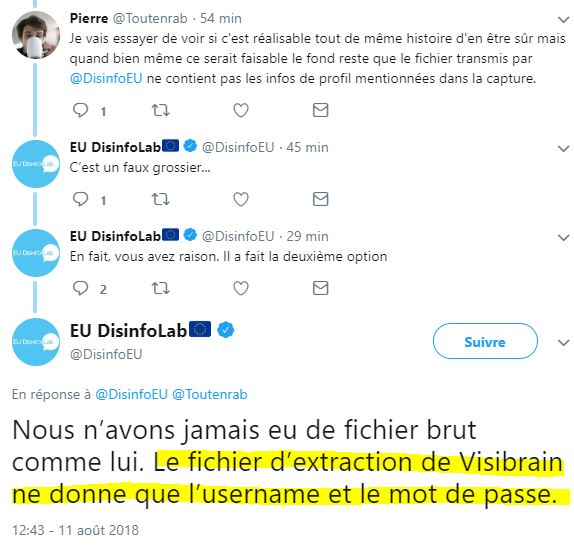
Comme ils ont fait une erreur sur « mot de passe » (sic.), ils corrigent :
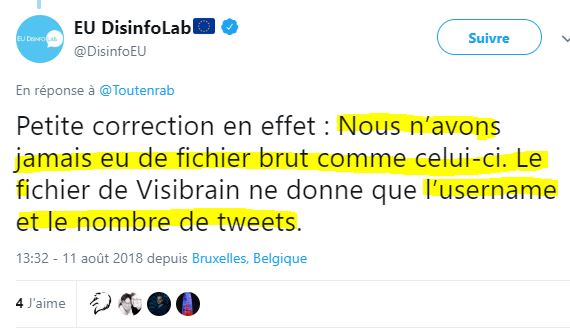
Maintenant, pour eux, Visibrain ne permet pas d’extraire autre chose que « l’username et le mot de passe »; oups, « l’username et le nombre de tweets ». Par chance, nous avons exposé le fonctionnement de ce logiciel Big Brother ici dans ce billet (source) :

(voir ici un exemple des données des fichiers produits par Visibrain)
Et on peut aussi exporter tous les followers, en les croisant (source) :

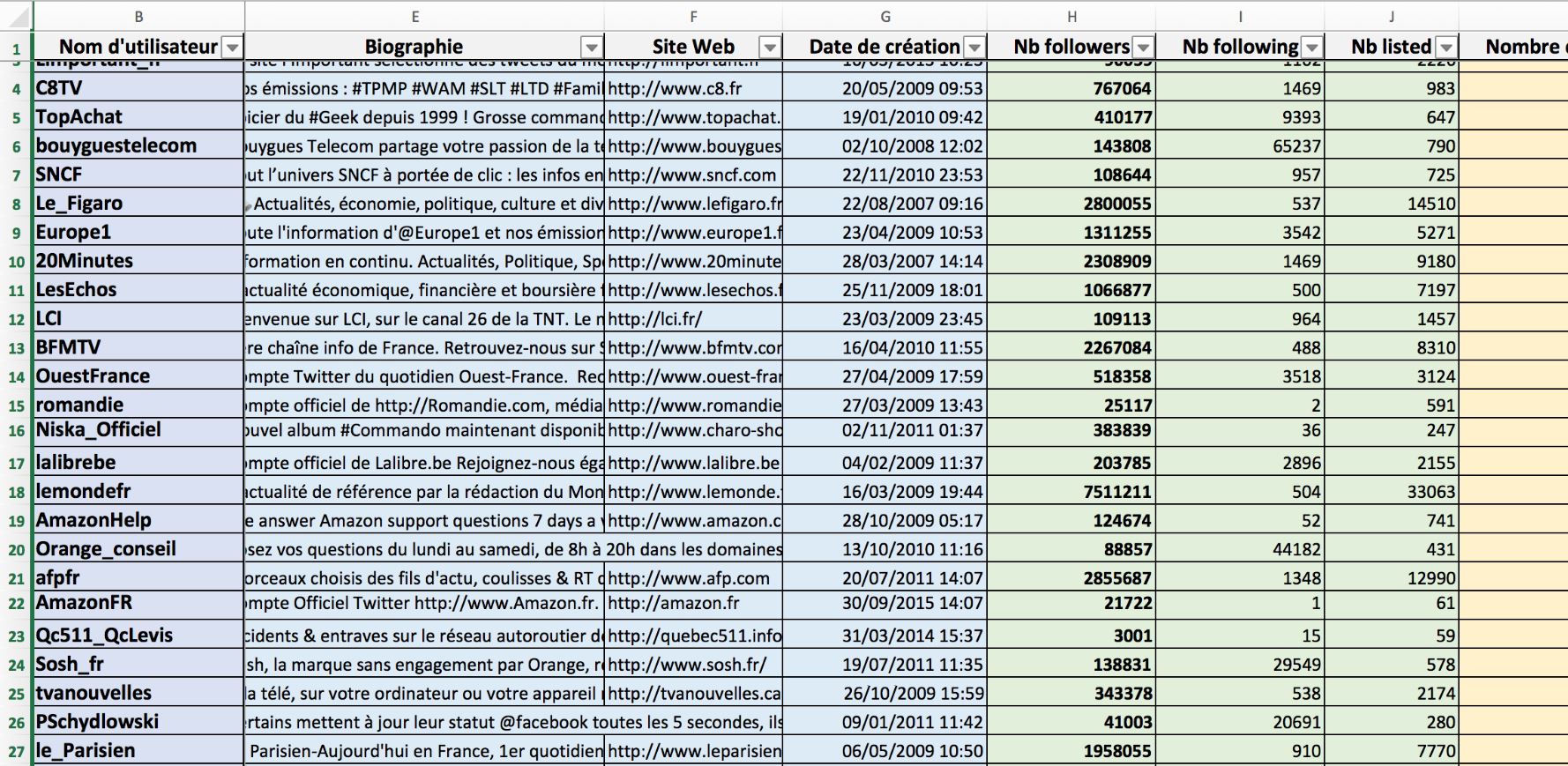
Un autre exemple des données Visibrain…
C’est d’ailleurs ce qu’ils expliquent… dans leur propre étude :
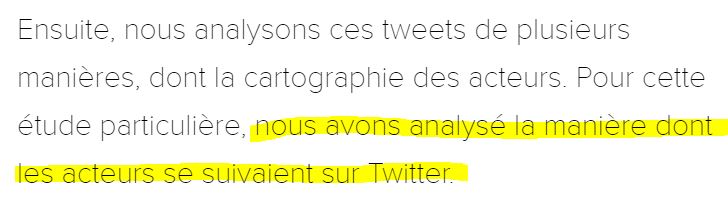
Rappelons que EU DisinfoLab est censé lutter contre la désinformation… Fact-checkons donc ses déclarations !
IV. Fact-checking du scandaleux démenti de Disinfo : « Pourquoi c’est faux »
Vous vous imaginez ce que doit ressentir face à ceci un citoyen lambda qui aurait réalisé le même genre de travaux que nous… Ou tout simplement les twittos fichés qui ont téléchargé le fichier et ont vu de leurs propre yeux ce que DisinfoLab cherche insidieusement à démentir ?
Précisons également que, selon leur site, l’équipe du DisinfoLab est très limitée, que Nicolas Vanderbiest est le cofondateur de l’association, et la seule « caution scientifique » (bien qu’il soit encore étudiant doctorant, diplômé en information et communication). Il a été pratiquement la seule personne à communiquer des informations techniques sur Twitter sur l’étude en cours :

Comme il l’avait annoncé, le chercheur a donc diffusé sur Twitter les données détaillées de l’étude DisinfoLab le 5 août (source) (Preuve ici) : (TWEET SUPPRIMÉ par Nicolas Vanderbiest) :
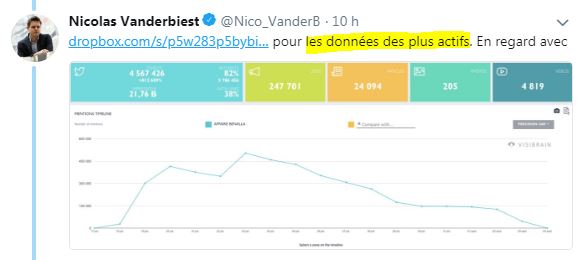
Note : Nicolas Vanderbiest a supprimé de très nombreux tweets « pour cacher ses erreurs » – espérons que la CNIL et la Justice demanderont bien à Twitter l’historique complète de toutes ses suppressions des derniers jours.
Il a donc par ce tweet d’abord partagé publiquement via Dropbox « Data brutes.csv », le fichier des 55 000 plus gros diffuseurs de Tweets et Retweets (ayant diffusé plus de 7 (re)tweets sur l’affaire Benalla), avec toutes leurs informations personnelles :
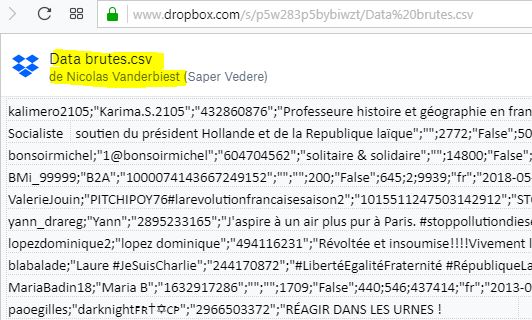

Cliquez pour agrandir. On a le nom de l’auteur et on voit les informations sensibles « que EU DisinfoLab n’a jamais eu »
Ce fichier qui n’a jamais existé contient ces 14 données en colonne :
- l’username / libellé du compte (le @),
- le nom public,
- « listed »l’id,
- la biographie du profil,
- la localisation,
- le nombre de followers,
- le statut vérifié,
- le nombre de comptes suivis,
- « listed » (?),
- le nombre de tweets du compte,
- la langue,
- la date de création du compte,
- le site internet,
- le nombre de Tweets et Retweets sur Benalla
De plus, au vu la gravité la chose, nous avons organisé un réseau de témoins tiers de confiance pour prouver la véracité de ce fichier, en vue de notre plainte à la CNIL, nous doutant bien que les auteurs finiraient par le supprimer, et étaient probablement capables de nier son existence… #PasDeBol
Et nous avons bien fait, vu qu’il est désormais possible au vu de leurs tweets que DisinfoLab ait détruit détruit les preuves de leurs agissements pour faire échec à l’enquête judiciaire et de la CNIL – nous le verrons. Nous tenons si besoin le fichier à la disposition de la CNIL (avant de bien entendu le détruire).
Ensuite, Nicolas Vanderbiest a récidivé : il a diffusé publiquement le fichier « ActeursClassés.xlsx » (source – archive) :
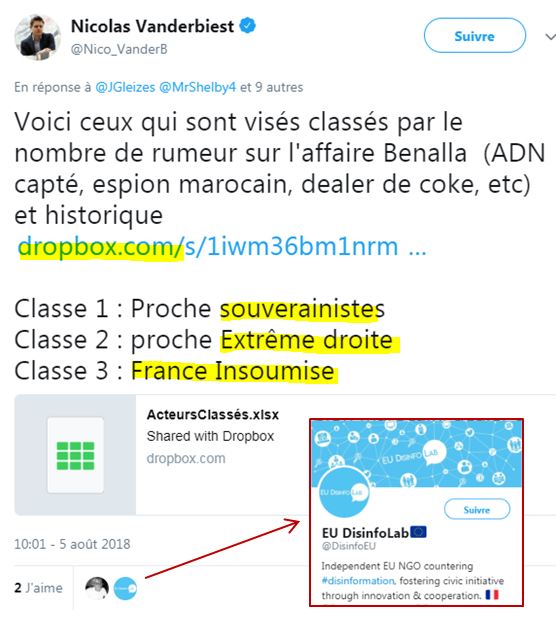
à savoir un fichier avec les 3 392 plus gros twitteurs sur Benalla (qui sont donc surtout des retwitteurs), auxquels il a attribué une couleur politique via un algorithme qu’il a créé : 1 pour souverainistes (sic. – c’est la droite Républicaine), 2 pour Extrême-droite et 3 pour la France insoumise !
Et son tweet a été « liké » par EU DisinfoLab…
Voici le contenu du fichier :

Et ici plus de très gros comptes classés par DisinfoLab comme « France Insoumise » (qui nous excuseront, nous l’espérons, de cette indication) :
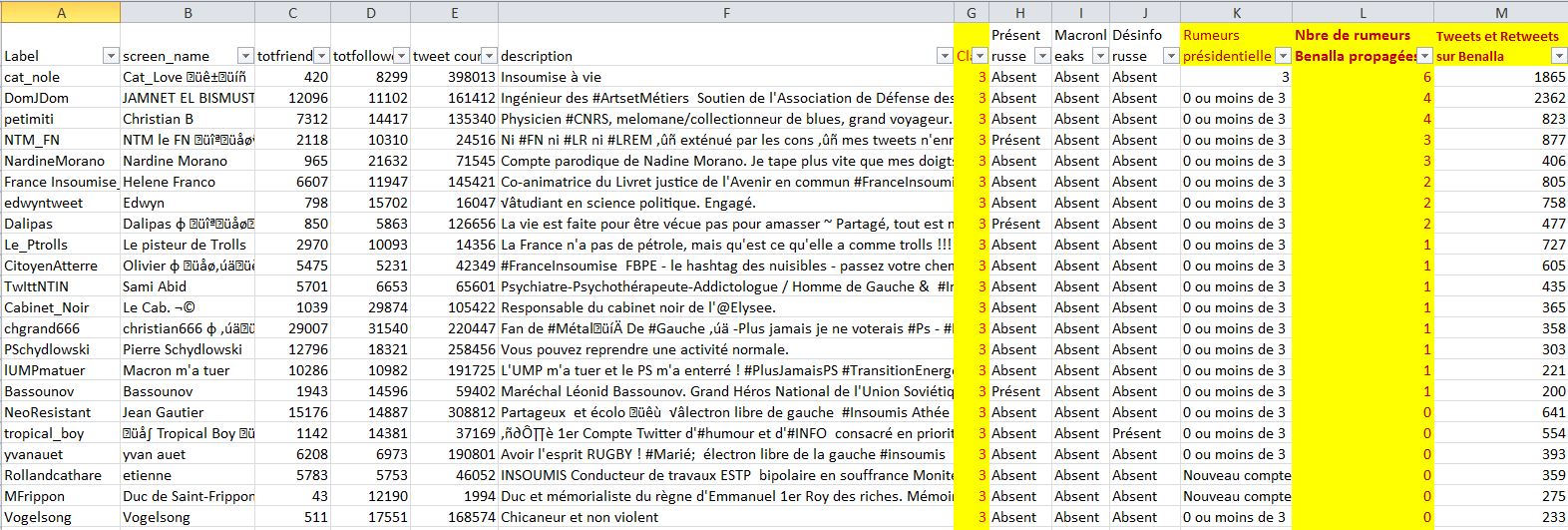
Ce fichier qui n’a jamais existé contient ces 13 données en colonne :
- l’username / libellé du compte (le @),
- le nom public,
- le nombre de comptes suivis,
- le nombre de followers,
- le nombre de tweets du compte,
- la biographie du profil,
- la « classe » politique attribuée par Disinfo
- « Présent russe » (russophile ?)
- Présent dans la diffusion « Macronleaks »
- Nombre de « Désinfo russe »
- nombre de « Rumeurs présidentielle »
- « Nombre de rumeurs Benalla propagées »
- le nombre de Tweets et Retweets sur Benalla
Ce sont ces deux fichiers que Nicolas Vanderbiest (fondateur du EU DisinfoLab) a supprimés.
Ce n’est qu’ensuite que le compte EU DisinfoLab a publié les 2 autres fichiers – les mêmes mais sans les données personnelles de la biographie ni le classement politiques (fichiers « Data brutes 1 – 47.xlsx » et « Rumeurs & items.xlsx »). Avant de le supprimer rapidement – vu qu’ils comprennent les identifiants des comptes (source) :

Ainsi, il y a bien eu 4 fichiers diffusés par cette officine, pas 3. Plus aucun n’est accessible (il faudrait donc qu’ils arrêtent de dire qu’on peut vérifier facilement dans leurs tweets, jouant de la confusion)
Nous avons déjà expliqué tout ceci dans ce billet de jeudi dernier.
Et Disinfo a publiquement reconnu ce problème de fichiers (source – d’autres exemples ici sur les fichiers « officiels ») :

Ah, il y a des fichiers « non officiels » – qui sortent d’où… ?
Ils avaient même répondu à Aude Lancelin (source) :
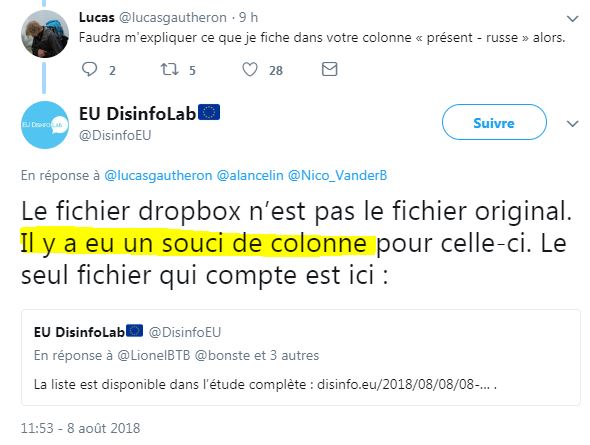
Oui un petit « souci de colonne »… Mais c’est à cause de nous peut-être ?
Et ceci ? (source)
Ah, ce fichier Dropbox donc ?
Mais qui donc a bien pu le diffuser ???
Ainsi, en résumé : Nicolas Vanderbiest, le cofondateur et chercheur du DisinfoLab a diffusé 2 fichiers :
- « Data brutes.csv » : contenant de nombreuses informations personnelles sensibles récupérées des profils publics de Twitter, dont la biographie, pour 55000 comptes ;
- « ActeursClassés.xlsx » : contenant les mêmes informations personnelles sensibles, complétées d’une classification politique qu’il a lui même réalisée (en indiquant un chiffre 1, 2 ou 3), pour plus de 3000 comptes.
Il les a supprimés au bout de plusieurs jours. Le compte DisinfoLab a ensuite diffusé 2 autres fichiers (« Data brutes 1-47.xlsx » et « Rumeurs & items.xlsx« ), avec bien moins de données personnelles, avant, également, de les supprimer.
Afin que tout le monde comprenne la gravité de ce genre de fichiers, nous avons donc réalisé notre tweet avec un extrait des deux premiers fichiers, diffusés par Nicolas Vanderbiest.
V. Fact-checking collaboratif du tableau de notre tweet
Le mieux est de laisser les twittos qui disposent du fichier original « Data brutes.csv » (à ne pas confondre avec le fichier épuré « Data brutes 1 – 47.xlsx ») de vérifier notre travail – que nous republions, en rajoutant les numéros de ligne du fichier original pour une vérification aisée – les voici :
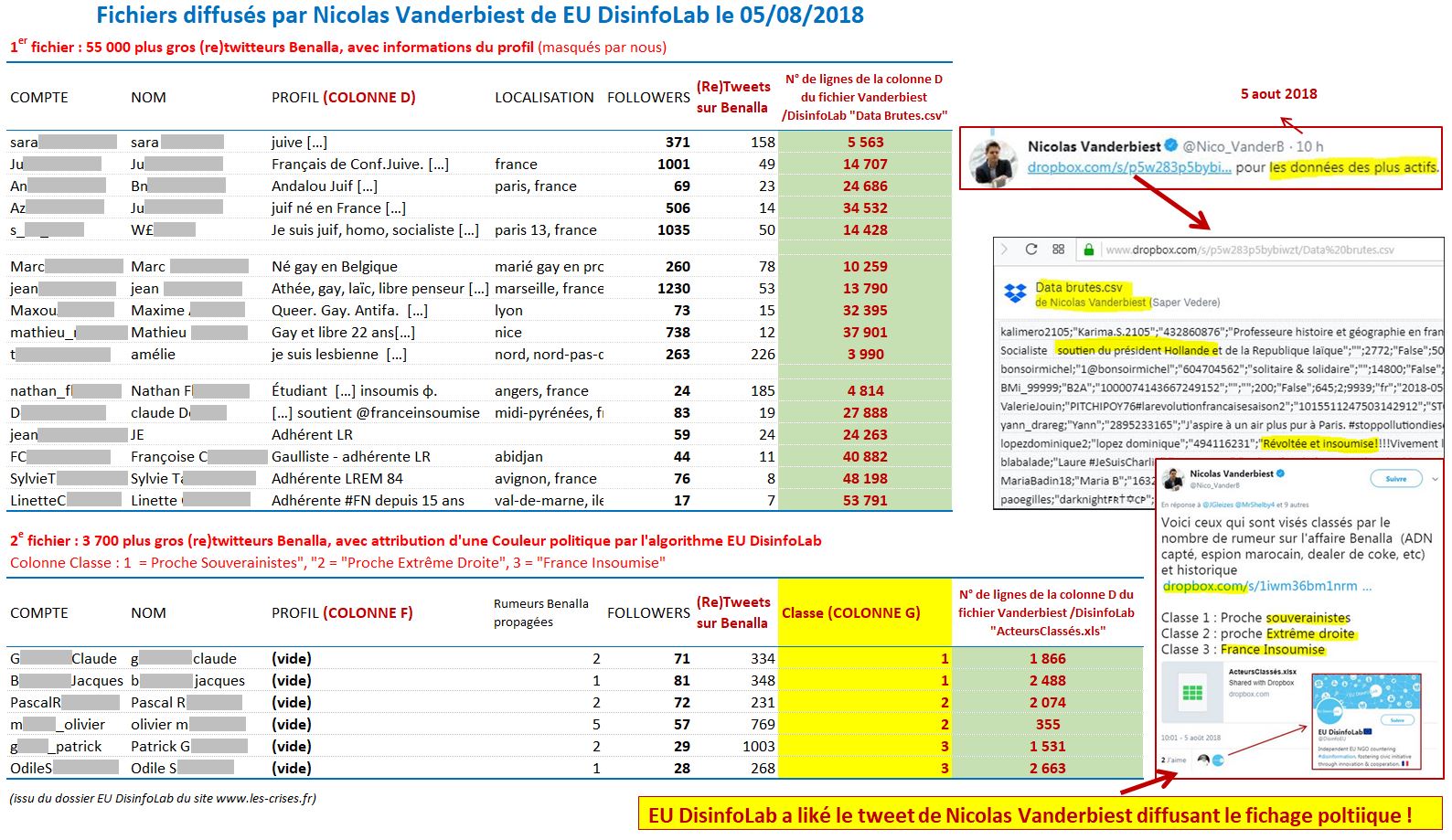
Cliquez pour agrandir.
N.B. attention sur quelques comptes, il y a des sauts de ligne dans la biographie, veillez donc à bien aller au bout de la cellule si besoin. Nous avons explicité dans la capture le titre de la colonne sur les Tweets Benalla (« in filtergetvalue tweet count »)
Nous mettrons les copies d’écran en réponse ici.
VI. Plainte
Le 10 aout, Nicolas Vanderbiest présente ses excuses, retweeté par DisinfoLab :

Au vu de tout ceci, on comprendra notre étonnement quand nous avons reçu ce matin, 11 aout à à 9h00, ce message diffamatoire et menaçant de Nicolas Vanderbiest :
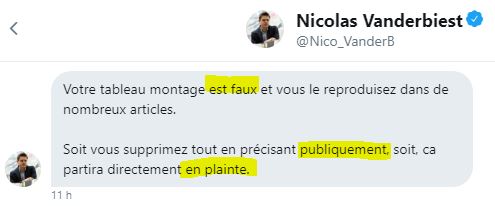
En réponse, je lui ai fait part de mon étonnement, et je lui ai demandé ce qu’il considérait comme faux :
Je n’ai reçu aucune réponse de sa part 8 heures après.
Je reste stupéfait, car, non seulement j’ai vu son fichier « Data Brutes.csv », mais, plus fort, s’il l’a supprimé sur Dropbox (qui est un hébergement en ligne) depuis 3 jours, il se trouve que j’ai toujours dans mon navigateur l’onglet ouvert sur ce même fichier Dropbox (qui n’a pas encore été effacé, n’ayant pas actualisé la page ; et il est impossible de modifier ce fichier) :
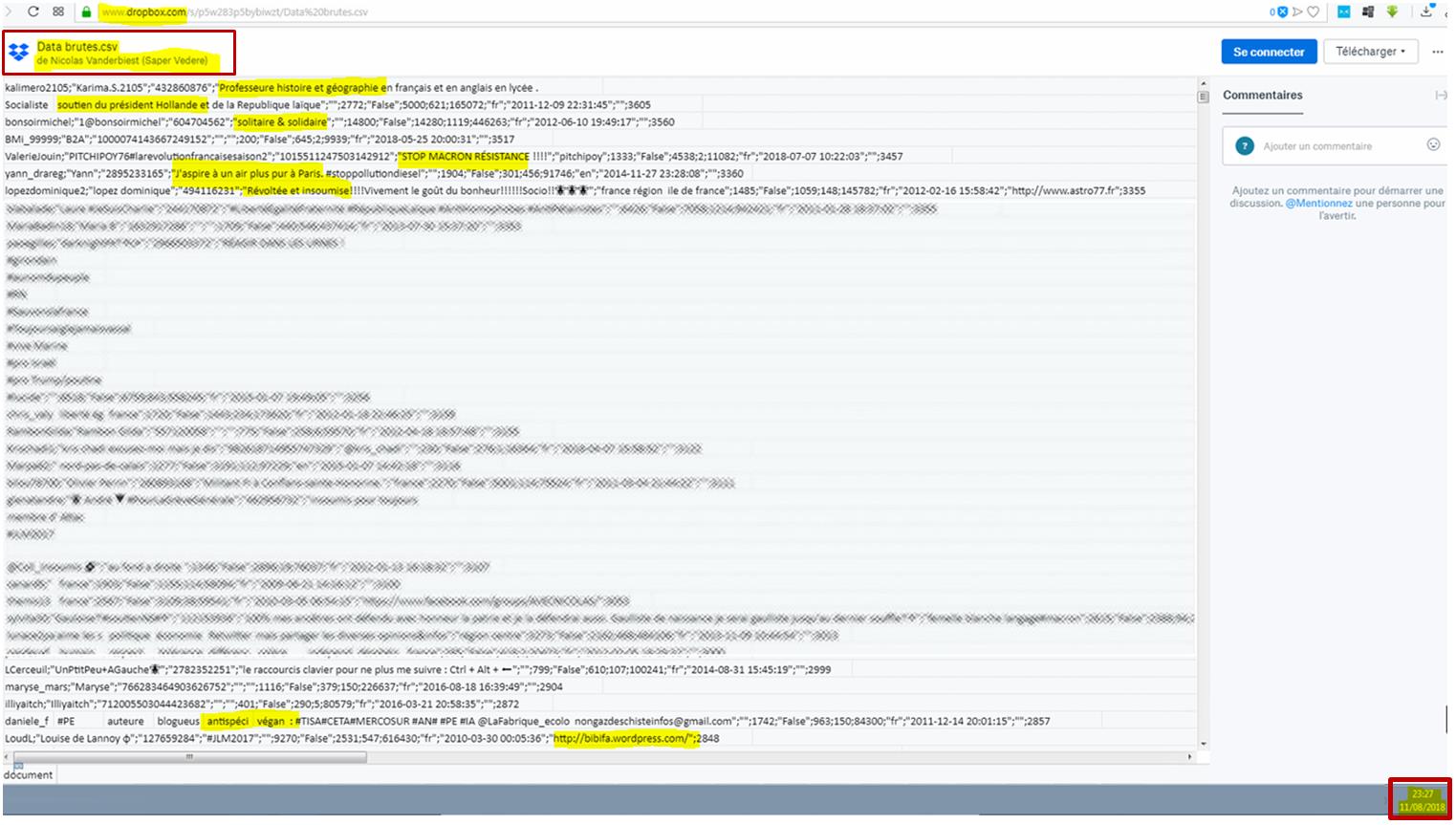
On voit que ce fichier est rempli de données personnelles sensibles de 55 000 personnes – et qu’il comprend le nom du titulaire du compte qui l’a mis en ligne :

Bref, comme il me demandait une mise au point publique, elle est donc faite. De rien.
Il est quand même stupéfiant que Twitter ait donné 125 000 $ à cette officine pour « lutter contre la désinformation » ! Nous allons leur demander des comptes au vu de l’énorme désinformation produite.

En plus c’était l’argent des publicités achetées à Twitter par RT et Sputnik ! #Kafka
Du coup, il est bien évident que nous portons plainte contre l’officine EU DisinfoLab pour diffamation :

Vous pouvez participer aux frais de justice par un paiement à notre avocat ici (même modeste). Merci d’avance.
P.S. au vu de ce comportement hautement suspect, nous continuerons bien entendu nos investigations sur cette officine.
(Billet édité)









Commentaire recommandé
Bravo ! Belle riposte ! Il faut leur rentrer dans le lard, et leur faire cracher leur mensonge.
Ce n’est plus une histoire belge. C’est le Malin qui montre le bout de son oreille.
Vous portez plainte, nous sommes avec vous ! Ista officina est delenda.
120 réactions et commentaires - Page 2
rhoo, énorme, ignorer la loi à ce point, risquer de nuire à autrui, puis prendre les gens pour des perdreaux, vraiment leurs freins moraux ne passent plus au contrôle technique.
Pour les constats, un huissier c’est mieux qu’un réseau de tiers, même si c’était un excellent réflexe.
Une question, vu qu’on pratique avec ardeur les mises en accusation baillons de ces propagandistes, il serait aussi intéressant de récupérer nos sous à l’issu des procédures judiciaires histoire
1) que cela ne coute pas au gens de faire respecter une once de moralité sur internet.
2) que le site ne fonctionne pas avec ces bouts de ficelles.
Pourquoi ne pas leur faire payer les frais de justice ?
+4
AlerterIl y a un fort risque de retour de flamme sur ce sujet ! Les vieux réflexes des médias peuvent revenir, et la controverse peut être étouffée par le « complotisme » (et la vérité réécrite au passage).
Sur le fond de l’affaire, on peut considérer que même cette histoire de fichage/fake news -et pourtant elle est grave- est secondaire par rapport à l’affaire elle-même : le problème n’est ni les agissements ni les avantages de Benalla, c’est le fait que Macron était en train de réformer la protection présidentielle, et de créer une sorte de police politique à sa botte (ou plutôt une milice) en-dehors de tout cadre institutionnel, en bousculant les institutions par des méthodes honteuses (insultes, pressions), parce qu’il a placé un caïd du civil pour chapeauter tout ça.
Source : https://www.youtube.com/watch?v=e4nSppPEki8
+4
AlerterCe travail de traitement de données est fait par d’autres, avec des moyens bien supérieurs techniquement et humainement, internet est le plus puissant outil d’acquisition de données à l’heure actuelle sur la population mondiale à cette différence que ce travail de traitement et gestion des données reste très sensible et donc très très confidentiel.
Le travail produit par le site en question est non seulement d’une médiocre qualité mais est de plus rendu public… .
+0
AlerterOla, Nicolas Vanderbiest a démissionné:
https://www.lavenir.net/cnt/dmf20180812_01208833/l-affaire-benalla-s-invite-a-l-ucl
et en passant, j’adore l’objectivité de l’article de l’Avenir (un des grands journaux en Belgique)!!
+2
AlerterEt bien pour une fois, je ne cautionne pas ce qui pour moi s’apparente à une cabale injustifiée, et ceci pour plusieurs raisons.
– Le fichier ne contient que des informations publiques. On ne va pas faire les ignares : on sait tous que ces données sont utilisés, que Twitter a une API, etc. Que des gens récupèrent ce contenu pour en faire des études – mêmes fausses – n’est franchement pas surprenant, et je doute même que la CNIL y trouvera quelque chose à redire.
– Prétendre qu’il s’agit de fichage, je trouve ça abusif. C’est une n-ième étude faite par des amateurs, et oui, pour faire des études, ca passe souvent par des fichiers Excel. Il y a bien la colonne « biographie », mais encore une fois, personne ne peut faire semblant d’ignorer qu’il s’agit d’une donnée publique.
– La notation ou la catégorisation des profils Twitter est-elle si choquante ? Toutes les boites le font et sur tous les sujets : Twitter le fait pour cibler ses pubs, Facebook, Google, etc. Est-ce un fichage politique ? Pas vraiment puisqu’il se base sur des informations que les internautes ont choisi de divulguer.
– La réaction des intéressés est stupide et peut-être mensongère, mais de toute évidence, ils paniquent devant l’ampleur de l’attaque. Qu’est-ce qu’on leur reproche ? D’avoir fait une étude basée sur des informations publiques divulguées consciemment par les internautes. Ca ne casse pas des briques.
– On s’oriente vers une cabale qui me semble excessive. Des noms de personne sont jetés en pature, des liens plus ou moins étayés sont faits entres divers entités et différentes personnes. Bref, la meute est lancée et c’est déplorable.
– On s’attaque à des « petits joueurs » dans le traitement de données, juste pour 55000 lignes d’un fichier Excel. Si on voulait vraiment pousser plus loin, on devrait s’attaquer à Twitter, et voir par exemple s’il n’y a pas un mécanisme de blocage des informations via l’API. Bref, des propositions concrètes, qu’elles soient techniques ou juridiques. De la même façon, attaquer les médias qui reprennent ces infos sans vérifier me semblerait plus pertinent.
– Le dépot de plainte pour diffamation me semble aussi excessif. C’est vache. Je ne suis même pas sûr que le type ait fait une vraie bêtise à la base, hormis la panique liée à la polémique. Pour lui les données de profils et les tweets sont considérés comme publiques et sortent des données à caractère personnel puisqu’elles sont exposées ouvertement par les twittos. Je comprends ce raisonnement.
– Ensuite, je recommande à chacun de taper dans Google : « @votrenomtwitter » ext:xlsx
Vous verrez ainsi les fichiers Excel – et donc certains études dont vous avez fait l’objet. Surprise !
– Enfin, quitte à attaquer les applications de DataMining, je trouve ça dommage d’attaquer une boite française (ou belge peu importe) en premier, alors que les US font 100 fois pires. Je ne sais pas qui est derrière cette boite, mais il a du mérite de créer son marché en la matière sur un tel secteur. C’est mon côté patriote.
– En bref, je vois tous ces cris d’orfraie, et je ne peux m’empêcher de me dire que c’est hypocrite. Vous dévoilez tout de vous sur internet, et vous vous plaignez d’être « fiché » dans des bases de données et autres fichiers, n’est-ce pas risible ? Au mieux de la naiveté, au pire de la mauvaise foi.
– En matière de données à caractère personnel et de « fichage », il y a bien d’autres combats à mener. Même en France.
+0
AlerterAh bon ? Si ce n’est pas ce prétendu fichage qui pose problème, faudrait le dire à 90% des twittos alors car ça n’a pas été compris comme ça.
Je suis ok avec vous et je déplore la même chose : on se trompe de débat. Il y a deux questions :
a) Les conditions de financement des entreprises aux ONG (quel processus ? est-ce transparent ? etc.)
b) La reprise des études farfelues par les mass-medias.
Et éventuellement, en c)
– Le statut juridique de la non-information par Twitter des mouvements de données, mais bon, à mon avis c’est perdu d’avance car leur CGU sont clairs, même si UFC-QueChoisir vient de gagner une première partie de procès.
Tout le reste, c’est du buzz facile et de la mise au pilori d’individus.
+0
AlerterUne seule réponse Nico aux arguments que vous avez développés.
En quoi la protection des citoyens par l’anonymisation des données influt-il sur leur traitement qu’il soit sociale, économiques ou de recherche ???
Par ailleurs, quitte à se répéter sur cette question en évoquant un scénario cauchemardesque du 20ème siècle, il n’y a pas de gentil dans la longue liste des participants à la solution finale.
Que disinfolab admette sa faute et que ce genre de liste NOMINATIVE soit définitivement proscrite dans les faits et dans les esprits.
Ne pas saisir tout le danger dans une telle démarche qui se veut « scientifique » est incompréhensible, sauf à le désirer….
+0
AlerterA la une en belgique :
http://www.lalibre.be/actu/belgique/affaire-benalla-un-chercheur-belge-vivement-critique-5b7182225532692548a98d10
+1
Alerterayé, il reconnait avoir menti, meme si checknews trouve le moyen de le presenter limite en victime, faut pas demander l’impossible non plus ^^
http://www.liberation.fr/checknews/2018/08/13/les-fichiers-eu-disinfolab-donnent-ils-les-infos-sensibles-gay-lesbienne-juif-queer_1672409
+1
AlerterCe sont vraiment des champions de l’inversion accusatoire..
C’est tout juste si O Berruyer ne devrait pas s’excuser d’avoir eu le culot de ne pas accepter d’être accusé mensongèrement par EU Disinfolab…
+3
AlerterIl a fait une petite erreur Olivier, même juridiquement. Il la découvrira certainement plus tard.
+0
AlerterLes commentaires sont fermés.